

The vibecoders are becoming sentient
-
This is in no way new. 20 years ago I used to refer to some job postings as H1Bait because they'd have requirements that were physically impossible (like having 5 years experience with a piece of software <2 years old) specifically so they could claim they couldn't find anyone qualified (because anyone claiming to be qualified was definitely lying) to justify an H1B for which they would be suddenly way less thorough about checking qualifications.
Yeah companies have always been abusing H1B, but it seems like only recently is it so hard for CS grads to find jobs. I didn't have much trouble in 2010 and it was easy to hop jobs for me the last 10 years.
Now, not so much.
-
Yeah, this is my nightmare scenario. Code reviews are always the worst part of a programming gig, and they must get exponentially worse when the junior devs can crank out 100s of lines of code per commit with an LLM.
Also, LLMs are essentially designed to produce code that will pass a code review. It's output that is designed to look as realistic as possible. So, not only do you have to look through the code for flaws, any error is basically "camouflaged".
With a junior dev, sometimes their lack of experience is visible in the code. You can tell what to look at more closely based on where it looks like they're out of their comfort zone. Whereas an LLM is always 100% in its comfort zone, but has no clue what it's actually doing.
-
Nah, it's the microplastics.
Why not both
 ?
? -
I don't want to dismiss your point overall, but I see that example so often and it irks me so much.
Unit tests are your specification. So, 1) ideally you should write the specification before you implement the functionality. But also, 2) this is the one part where you really should be putting in your critical thinking to work out what the code needs to be doing.
An AI chatbot or autocomplete can aid you in putting down some of the boilerplate to have the specification automatically checked against the implementation. Or you could try to formulate the specification in plaintext and have an AI translate it into code. But an AI without knowledge of the context nor critical thinking cannot write the specification for you.
Tests are probably both the best and worst things to use LLMs for.
They're the best because of all the boilerplate. Unit tests tend to have so much of that, setting things up and tearing it down. You want that to be as consistent as possible so that someone looking at it immediately understands what they're seeing.
OTOH, tests are also where you figure out how to attack your code from multiple angles. You really need to understand your code to think of all the ways it could fail. LLMs don't understand anything, so I'd never trust one to come up with a good set of things to test.
-
It is not useless. You should absolutely continue to vibes code. Don't let a professional get involved at the ground floor. Don't inhouse a professional staff.
Please continue paying me $200/hr for months on end debugging your Baby's First Web App tier coding project long after anyone else can salvage it.
And don't forget to tell your investors how smart you are by Vibes Coding! That's the most important part. Secure! That! Series! B! Go public! Get yourself a billion dollar valuation on these projects!
Keep me in the good wine and the nice car! I love vibes coding.
Not me, I'd rather work on a clean code base without any slop, even if it pays a little less. QoL > TC
-
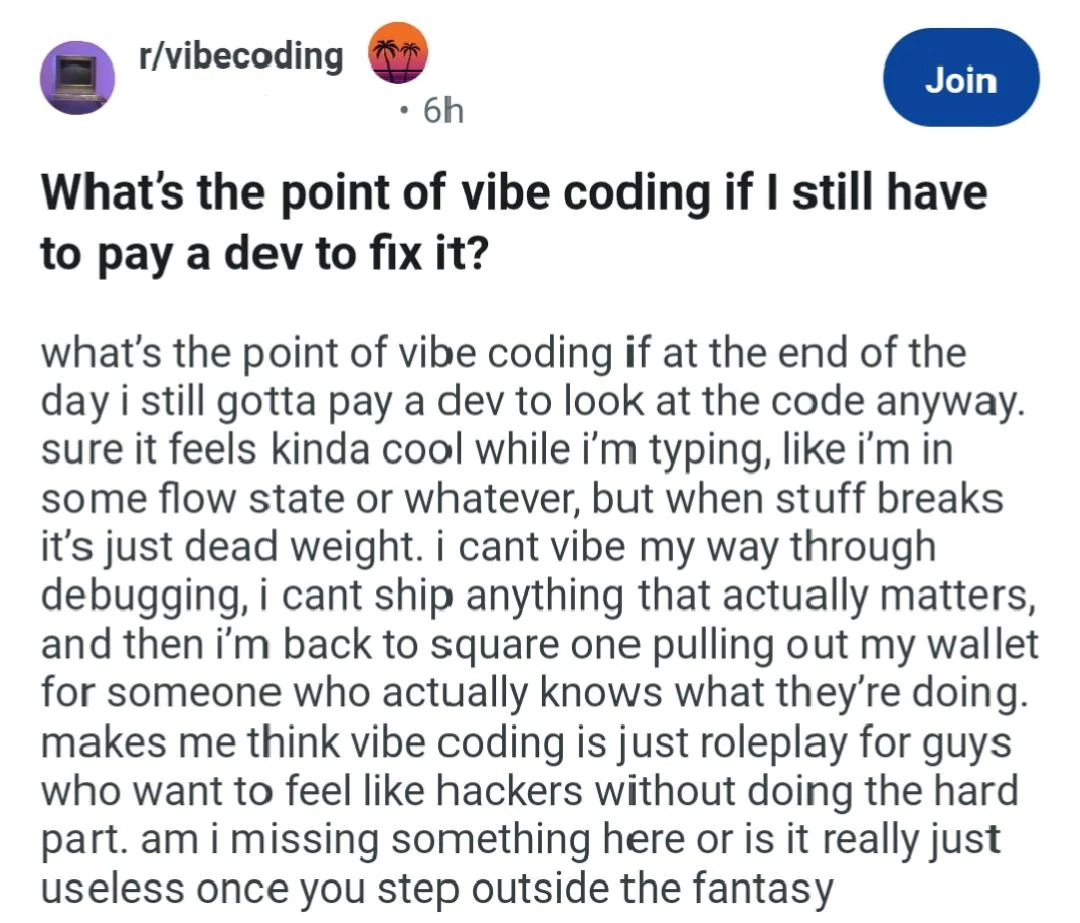
Can someone tell me what vibe coding is?
From what I understand, it's using an LLM for coding, but taken to an extreme. Like, a regular programmer might use an LLM to help them with something, but they'll read through the code the LLM produces, make sure they understand it, tweak it wherever it's necessary, etc. A vibe coder might not even be a programmer, they just get the LLM to generate some code and they run the code to see if it does what they want. If it doesn't, they talk to the LLM some more and generate some more code. At no point do they actually read through the code and try to understand it. They just run the program and see if it does what they want.
-
I'm entirely too trusting and would like to know what about the phrasing tips you off that it's fictional. Back on Reddit I remember so many claims about posts being fake and I was never able to tease out what distinguished the "omg fake! r/thathappened" posts from the ones that weren't accused of that, and I feel this is a skill I should be able to have on some level. Although taking an amusing post that wasn't real as real doesn't always have bad consequences.
But I mostly asked because I'm curious about the weird extra width on letters.
Interesting. Curious for a point of comparison how The Onion reads to you.
(Only a mediocre point of comparison I fear, but)
-
This post did not contain any content.wrote last edited by [email protected]
As a software developer, I've found some free LLMs to provide productivity boosts. It is a fairly hairpulling experience to not try too hard to get a bad LLM to correct itself, and learning to switch quickly from bad LLMs is a key skill in using them. A good model is still one that you can fix their broken code, and ask them to understand why what you provided them fixes it. They need a long context window to not repeat their mistakes. Qwen 3 is very good at this. Open source also means a future of customizing to domain, ie. language specific, optimizations, and privacy trust/unlimited use with enough local RAM, with some confidence that AI is working for you rather than data collecting for others. Claude Sonnet 4 is stronger, but limited free access.
The permanent side of high market cap US AI industry is that it will always be a vector for NSA/fascism empire supremacy, and Skynet goal, in addition to potentially stealing your input/output streams. The future for users who need to opt out of these threats, is local inference, and open source that can be customized to domains important to users/organizations. Open models are already at close parity, IMO from my investigations, and, relatively low hanging fruit, customization a certain path to exceeding parity for most applications.
No LLM can be trusted to allow you do to something you have no expertise in. This state will remain an optimistic future for longer than you hope.
-
I'm entirely too trusting and would like to know what about the phrasing tips you off that it's fictional. Back on Reddit I remember so many claims about posts being fake and I was never able to tease out what distinguished the "omg fake! r/thathappened" posts from the ones that weren't accused of that, and I feel this is a skill I should be able to have on some level. Although taking an amusing post that wasn't real as real doesn't always have bad consequences.
But I mostly asked because I'm curious about the weird extra width on letters.
-
As a software developer, I've found some free LLMs to provide productivity boosts. It is a fairly hairpulling experience to not try too hard to get a bad LLM to correct itself, and learning to switch quickly from bad LLMs is a key skill in using them. A good model is still one that you can fix their broken code, and ask them to understand why what you provided them fixes it. They need a long context window to not repeat their mistakes. Qwen 3 is very good at this. Open source also means a future of customizing to domain, ie. language specific, optimizations, and privacy trust/unlimited use with enough local RAM, with some confidence that AI is working for you rather than data collecting for others. Claude Sonnet 4 is stronger, but limited free access.
The permanent side of high market cap US AI industry is that it will always be a vector for NSA/fascism empire supremacy, and Skynet goal, in addition to potentially stealing your input/output streams. The future for users who need to opt out of these threats, is local inference, and open source that can be customized to domains important to users/organizations. Open models are already at close parity, IMO from my investigations, and, relatively low hanging fruit, customization a certain path to exceeding parity for most applications.
No LLM can be trusted to allow you do to something you have no expertise in. This state will remain an optimistic future for longer than you hope.
I think the key to good LLM usage is a light touch. Let the LLM know what you want, maybe refine it if you see where the result went wrong. But if you find yourself deep in conversation trying to explain to the LLM why it's not getting your idea, you're going to wind up with a bad product. Just abandon it and try to do the thing yourself or get someone who knows what you want.
They get confused easily, and despite what is being pitched, they don't really learn very well. So if they get something wrong the first time they aren't going to figure it out after another hour or two.
-
Why not both
?With a pinch of PFAS for good measure?
-
Nah, it's the microplastics.
Microplastics are stored in the balls.
-
No idea, but I am not sure your family member is qualified. I would estimate that a coding LLM can code as well as a fresh CS grad. The big advantage that fresh grads have is that after you give them a piece of advice once or twice, they stop making that same mistake.
What's this based on? Have you met a fresh CS graduate and compared them to an LLM? Does it not vary person to person? Or fuck it, LLM to LLM? Calling them not qualified seems harsh when it's based on sod all.
-
Interesting. Curious for a point of comparison how The Onion reads to you.
(Only a mediocre point of comparison I fear, but)
wrote last edited by [email protected]That's a bit difficult because I already go into anything from The Onion knowing it's intended to be humorous/satirical.
What I lack in ability to recognize satire or outright deception from posts written online, I make up for by reading comment threads: seeing people accuse things of being fake, seeing people defend it as true, seeing people point out the entire intention of a website is satire, seeing people who had a joke go over their heads get it explained... relying on the collective hivemind to help me out where I am deficient. It's not a perfect solution at all, especially since people can judge wrong—I bet some "omg so fake" threads were actually real, and some astroturf-type things written to influence others without real experience behind it got through as real.
-
I think the key to good LLM usage is a light touch. Let the LLM know what you want, maybe refine it if you see where the result went wrong. But if you find yourself deep in conversation trying to explain to the LLM why it's not getting your idea, you're going to wind up with a bad product. Just abandon it and try to do the thing yourself or get someone who knows what you want.
They get confused easily, and despite what is being pitched, they don't really learn very well. So if they get something wrong the first time they aren't going to figure it out after another hour or two.
In my experience, they're better at poking holes in code than writing it, whether that's green or brownfield.
I've tried to get it to make sections of changes for me, and it feels very productive, but when I time myself I find I spend probably more time correcting the LLM's work than if I'd just written it myself.
But if you ask it to judge a refactor, then you might actually get one or two good points. You just have to really be careful to double check its assertions if you're unfamiliar with anything, because it will lead you to some real boners if you just follow it blindly.
-
Not me, I'd rather work on a clean code base without any slop, even if it pays a little less. QoL > TC
I'm not above slinging a little spaghetti if it pays the bills.
-
No idea, but I am not sure your family member is qualified. I would estimate that a coding LLM can code as well as a fresh CS grad. The big advantage that fresh grads have is that after you give them a piece of advice once or twice, they stop making that same mistake.
Where is this coming from? I don't think an LLM can code at the level of a recent cs grad unless it's piloted by a cs grad.
Maybe you've had much better luck than me, but coding LLMs seem largely useless without prior coding knowledge.
-
I think the key to good LLM usage is a light touch. Let the LLM know what you want, maybe refine it if you see where the result went wrong. But if you find yourself deep in conversation trying to explain to the LLM why it's not getting your idea, you're going to wind up with a bad product. Just abandon it and try to do the thing yourself or get someone who knows what you want.
They get confused easily, and despite what is being pitched, they don't really learn very well. So if they get something wrong the first time they aren't going to figure it out after another hour or two.
But if you find yourself deep in conversation trying to explain to the LLM why it’s not getting your idea, you’re going to wind up with a bad product.
Yes. Kind of. It takes ( a couple of days) experience with LLMs to know that failing to understand your corrections means immediate delete and try another LLM. The only OpenAI llm I tried was their 120g open source release. It insisted that it was correct in its stupidity. That's worse than LLMs that forget the corrections from 3 prompts ago, though I also learned that is also grounds for delete over any hope for their usefulness.
-
He needs at least a decade of industry experience. That helps me find jobs.
It would be nice if software development were a real profession and people could get that experience properly.
-
In my experience, they're better at poking holes in code than writing it, whether that's green or brownfield.
I've tried to get it to make sections of changes for me, and it feels very productive, but when I time myself I find I spend probably more time correcting the LLM's work than if I'd just written it myself.
But if you ask it to judge a refactor, then you might actually get one or two good points. You just have to really be careful to double check its assertions if you're unfamiliar with anything, because it will lead you to some real boners if you just follow it blindly.
At work we've got coderabbit set up on our github and it has found bugs that I wrote. Sometimes the thing drives me insane with pointless comments, but just today found a spot that would have been a big bug in prod in like 3 months.