

AGI achieved 🤖


-
And yet they can seemingly spell and count (small numbers) just fine.
what do you mean by spell fine? They're just emitting the tokens for the words. Like, it's not writing "strawberry," it's writing tokens <302, 1618, 19772>, which correspond to st, raw, and berry respectively. If you ask it to put a space between each letter, that will disrupt the tokenization mechanism, and it's going to be quite liable to making mistakes.
I don't think it's really fair to say that the lookup 19772 -> berry counts as the LLM being able to spell, since the LLM isn't operating at that layer. It doesn't really emit letters directly. I would argue its inability to reliably spell words when you force it to go letter-by-letter or answer queries about how words are spelled is indicative of its poor ability to spell.
-
Yes but from same source also wife
That came later though, as in “I had dinner with the Mrs last night.”
-
But no "r" sound.
Correct. I didn’t say there was an r sound, but that it was going off of the spelling. I agree there’s no r sound.
-
Adding weights doesn't make it a fundamentally different algorithm.
We have hit a wall where these programs have combed over the totality of the internet and all available datasets and texts in existence.
There isn't any more training data to improve with, and these programs have stated polluting the internet with bad data that will make them even dumber and incorrect in the long run.
We're done here until there's a fundamentally new approach that isn't repetitive training.
wrote on last edited by [email protected]Transformers were pretty novel in 2017, I don't know if they were really around before that.
Anyway, I'm doubtful that a larger corpus is what's needed at this point. (Though that said, there's a lot more text remaining in instant messager chat logs like discord that probably have yet to be integrated into LLMs. Not sure.) I'm also doubtful that scaling up is going to keep working, but it wouldn't surprise that much me if it does keep working for a long while. My guess is that there's some small tweaks to be discovered that really improve things a lot but still basically like like repetitive training as you put it. Who can really say though.
-
Imagine asking a librarian "What was happening in Los Angeles in the Summer of 1989?" and that person fetching you ... That's modern LLMs in a nutshell.
I agree, but I think you're still being too generous to LLMs. A librarian who fetched all those things would at least understand the question. An LLM is just trying to generate words that might logically follow the words you used.
IMO, one of the key ideas with the Chinese Room is that there's an assumption that the computer / book in the Chinese Room experiment has infinite capacity in some way. So, no matter what symbols are passed to it, it can come up with an appropriate response. But, obviously, while LLMs are incredibly huge, they can never be infinite. As a result, they can often be "fooled" when they're given input that semantically similar to a meme, joke or logic puzzle. The vast majority of the training data that matches the input is the meme, or joke, or logic puzzle. LLMs can't reason so they can't distinguish between "this is just a rephrasing of that meme" and "this is similar to that meme but distinct in an important way".
Can you explain the difference between understanding the question and generating the words that might logically follow? I'm aware that it's essentially a more powerful version of how auto-correct works, but why should we assume that shows some lack of understanding at a deep level somehow?
-
You're talking about hallucinations. That's different from tokenization reflection errors. I'm specifically talking about its inability to know how many of a certain type of letter are in a word that it can spell correctly. This is not a hallucination per se -- at least, it's a completely different mechanism that causes it than whatever causes other factual errors. This specific problem is due to tokenization, and that's why I say it has little bearing on other shortcomings of LLMs.
No, I'm talking about human learning and the danger imposed by treating an imperfect tool as a reliable source of information as these companies want people to do.
Whether the erratic information is from tokenization or hallucinations is irrelevant when this is already the main source for so many people in their learning, for example, a new language.
-
That came later though, as in “I had dinner with the Mrs last night.”
Yes but it did come, and took place as the common usage. So much so that Ms. Is used to describe a woman both with and without reference to marital status.
I'm down with using Mrs. not to refer to marital status but imo just going with Ms. Is clearer and easier because of how deeply associated Mrs. Is with it.
-
what do you mean by spell fine? They're just emitting the tokens for the words. Like, it's not writing "strawberry," it's writing tokens <302, 1618, 19772>, which correspond to st, raw, and berry respectively. If you ask it to put a space between each letter, that will disrupt the tokenization mechanism, and it's going to be quite liable to making mistakes.
I don't think it's really fair to say that the lookup 19772 -> berry counts as the LLM being able to spell, since the LLM isn't operating at that layer. It doesn't really emit letters directly. I would argue its inability to reliably spell words when you force it to go letter-by-letter or answer queries about how words are spelled is indicative of its poor ability to spell.
what do you mean by spell fine?
I mean that when you ask them to spell a word they can list every character one at a time.
-
I'm still puzzled by the idea of what mess this war was if at times you had someone still not clearly identifiable, but that close you can do a sheboleth check on them, and that at any moment you or the other could be shot dead.
Also, the current conflict of Russia vs Ukraine seems to invent ukrainian 'паляница' as a check, but as I had no connection to actual ukrainians and their UAF, I can't say if that's not entirely localized to the internet.
wrote on last edited by [email protected]Have you ever been to a very dense jungle or forest... at midnight?
Ok, now, drop mortar and naval artillery shells all over it.
For weeks, or months.
The holes this creates are commonly used by both sides as cover and concealment.
Also, its often raining, sometimes quite heavily, such that these holes will up with water, and you are thus soaking wet.
Ok, now, add in pillboxes and bunkers, as well as a few spiderwebs of underground tunnel networks, many of which have concealed entrances.
You do not have a phone. GPS does not exist.
You might have a map, which is out of date, and you might have a compass, if you didn't drop or break it.
A radio is either something stationary, or is the size and weight of approximately, somewhat less than a miniature refrigerator, and one bullet or good piece of shrapnel will take it out of commission.
Ok, now, you and all your buddies are either half starving or actually starving, beyond exhausted, getting maybe an average of 2 to 4 hours of sleep, and you, and the enemy, are covered in dirt, blood and grime.
Also, you and everyone else may or may not have malaria, or some other fun disease, so add shit and vomit to the mix of what everyone is covered in.
Ok! Enjoy your 2 to 8 week long camping trip from hell, in these conditions... also, kill everyone that is trying to kill you, soldier.
-
then 14b, man sooo close...
 wrote on last edited by [email protected]
wrote on last edited by [email protected]I wonder how QWEN 3.0 performs cause it surpasses Deepseek apparently
-
Next step how many r in Lollapalooza
 wrote on last edited by [email protected]
wrote on last edited by [email protected]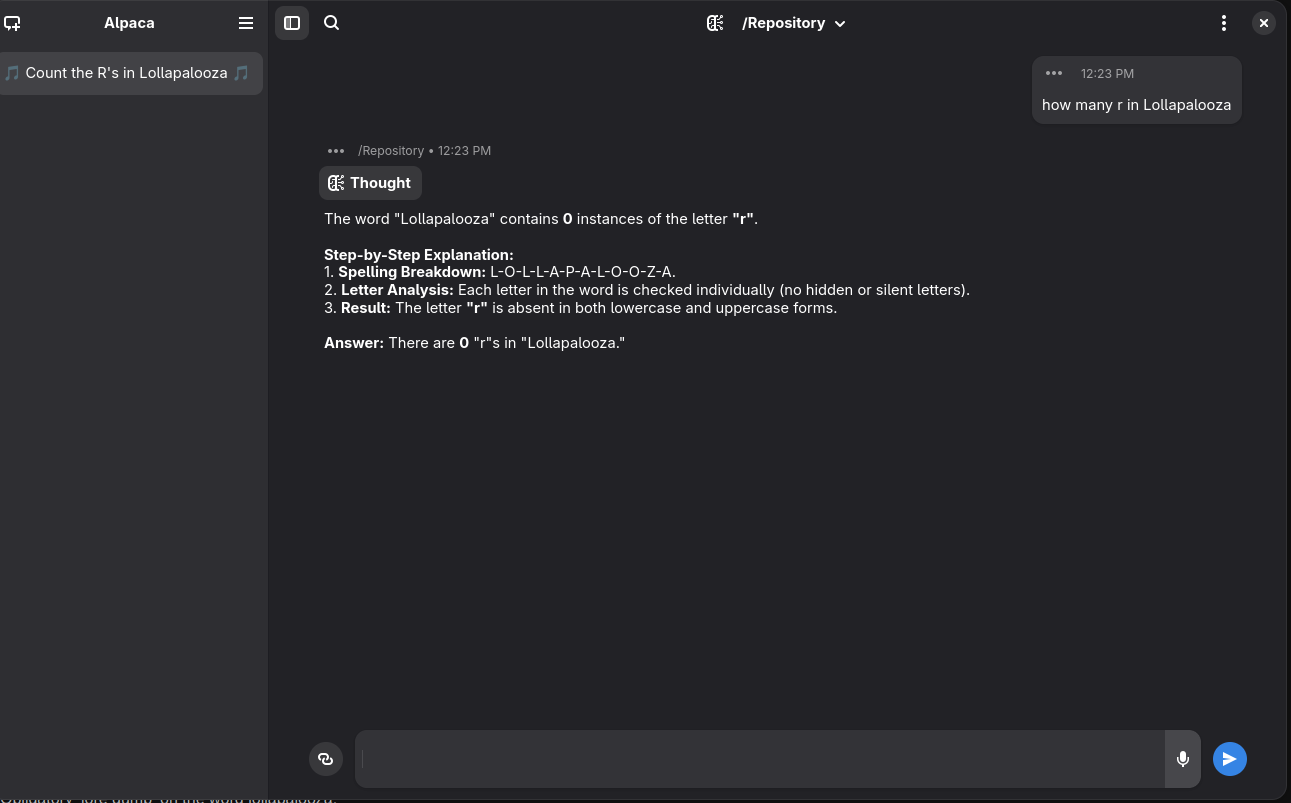
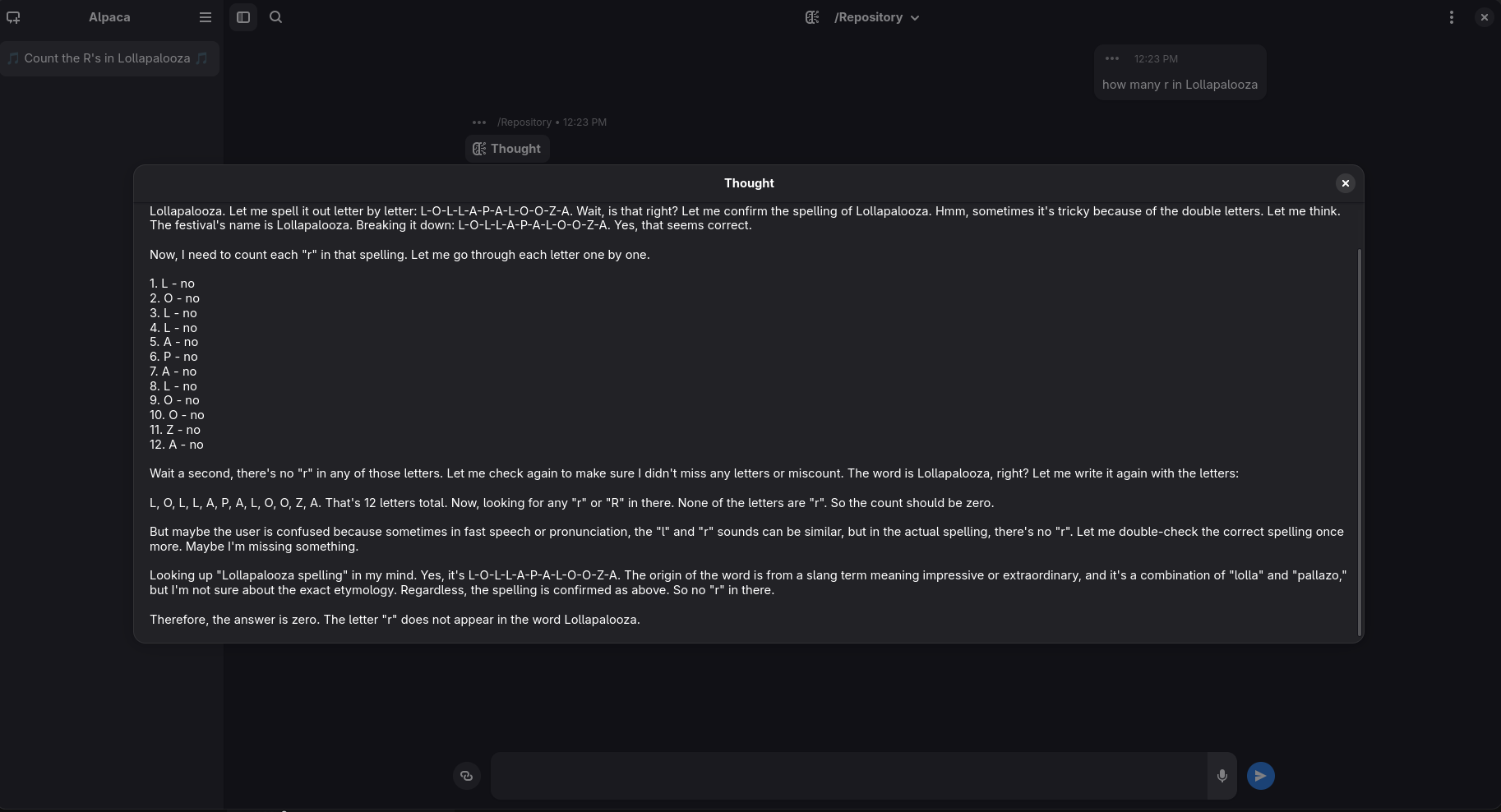
With Reasoning (this is QWEN on hugginchat it says there is Zero)
-
Yes but it did come, and took place as the common usage. So much so that Ms. Is used to describe a woman both with and without reference to marital status.
I'm down with using Mrs. not to refer to marital status but imo just going with Ms. Is clearer and easier because of how deeply associated Mrs. Is with it.
That’s up to you, I much prefer Mrs. Ms. feels somehow condescending to me.
-
We gotta raise the bar, so they keep struggling to make it “better”

::: spoiler My attempt
0000000000000000 0000011111000000 0000111111111000 0000111111100000 0001111111111000 0001111111111100 0001111111111000 0000011111110000 0000111111000000 0001111111100000 0001111111100000 0001111111100000 0001111111100000 0000111111000000 0000011110000000 0000011110000000Btw, I refuse to give my money to AI bros, so I don’t have the “latest and greatest”
:::
wrote on last edited by [email protected]Tested on ChatGPT o4-mini-high
It sent me this
0 0 0 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 1 1 1 0 0 1 1 1 0 0 0 0 0 0 0 1 1 1 0 0 0 0 1 1 1 0 0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1 0 0 0 0I asked it to remove the spaces
0001111100000000 0011111111000000 0011111110000000 0111111111100000 0111111111110000 0011111111100000 0001111111000000 0011111100000000 0111111111100000 1111111111110000 1111111111110000 1111111111110000 1111111111110000 0011100111000000 0111000011100000 1111000011110000I guess I just murdered a bunch of trees and killed a random dude with the water it used, but it looks good
-
I really like checking these myself to make sure it’s true. I WAS NOT DISAPPOINTED!
(Total Rs is 8. But the LOGIC ChatGPT pulls out is ……. remarkable!)

Try with o4-mini-high. It’s made to think like a human by checking its answer and doing step by step, rather than just kinda guessing one like here
-
And yet they can seemingly spell and count (small numbers) just fine.
The problem is that it's not actually counting anything. It's simply looking for some text somewhere in its database that relates to that word and the number of R's in that word. There's no mechanism within the LLM to actually count things. It is not designed with that function. This is not general AI, this is a Generative Adversarial Network that's using its vast vast store of text to put words together that sound like they answer the question that was asked.
-
I really like checking these myself to make sure it’s true. I WAS NOT DISAPPOINTED!
(Total Rs is 8. But the LOGIC ChatGPT pulls out is ……. remarkable!)

-
I want an option to select Marvin the paranoid android mood: "there's your answer, now if you could leave me to wallow in self-pitty"
Here I am, emissions the size of a small country, and they ask me to count letters...
-
ohh god, I never through to ask reasoning models,
DeepSeekR17b was gold too

It's painful how Reddit that is...
So,
Now,
Alright,
-
I really like checking these myself to make sure it’s true. I WAS NOT DISAPPOINTED!
(Total Rs is 8. But the LOGIC ChatGPT pulls out is ……. remarkable!)
What is this devilry?
-
I want an option to select Marvin the paranoid android mood: "there's your answer, now if you could leave me to wallow in self-pitty"
Lol someone could absolutely do that as a character card.