

It still can’t count the Rs in strawberry, I’m not worried.
-
[email protected]replied to [email protected] last edited by
I mean I tested it out, even tbough I am sure your trolling me and DeepSeek correctly counts the R's
-
[email protected]replied to [email protected] last edited by
Not trolling you at all:
-
[email protected]replied to [email protected] last edited by
Non thinking prediction models can't count the r's in strawberry due to the nature of tokenization.
However openai o1 and deep seek r1 can both reliably do it correctly
-
[email protected]replied to [email protected] last edited by
Yes it can
-
[email protected]replied to [email protected] last edited by
Screenshots please
-
[email protected]replied to [email protected] last edited by
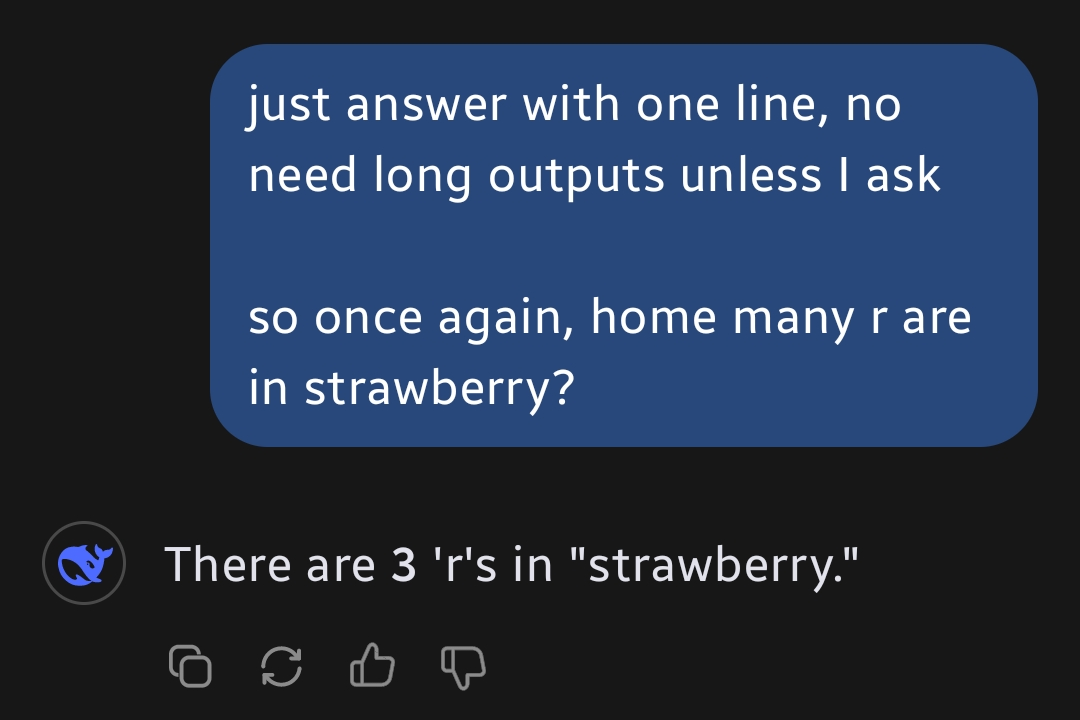
-
[email protected]replied to [email protected] last edited by
It searches the internet for cats without tails and then generates an image from a summary of what it finds.
That's how this Machine Learning progam works
-
[email protected]replied to [email protected] last edited by
Clearly not the first try
")
-
[email protected]replied to [email protected] last edited by
“Again” so it failed the first time. Got it.
-
[email protected]replied to [email protected] last edited by
It didn't, I just wanted a short reply. Though it failed when I asked again at the same chat. But when asked to split the word to 2 parts it became sure that the correct answer is 3.
-
[email protected]replied to [email protected] last edited by
That’s a lot of processing just to count letters. Hopefully it can add numbers without splitting the number
-
[email protected]replied to [email protected] last edited by
so.... with all the supposed reasoning stuff they can do, and supposed "extrapolation of knowledge" they cannot figure out that a tail is part of a cat, and which part it is.
-
[email protected]replied to [email protected] last edited by
That isn't at all how something like a diffusion based model works actually.
-
[email protected]replied to [email protected] last edited by
So what training data does it use?
They found data to train it that isn't just the open internet?
-
[email protected]replied to [email protected] last edited by
The "reasoning" you are seeing is it finding human conversations online, and summerizing them
-
[email protected]replied to [email protected] last edited by
Regardless of training data, it isn't matching to anything it's found and squigglying shit up or whatever was implied. Diffusion models are trained to iteratively convert noise into an image based on text and the current iteration's features. This is why they take multiple runs and also they do that thing where the image generation sort of transforms over multiple steps from a decreasingly undifferentiated soup of shape and color. My point was that they aren't doing some search across the web, either externally or via internal storage of scraped training data, to "match" your prompt to something. They are iterating from a start of static noise through multiple passes to a "finished" image, where each pass's transformation of the image components is a complex and dynamic probabilistic function built from, but not directly mapping to in any way we'd consider it, the training data.
-
[email protected]replied to [email protected] last edited by
Oh ok so training data doesn't matter?
Or only when it makes your agument invalid?
Tell me how you moving the bar proves that AI is more intelligent than the sum of its parts?
-
[email protected]replied to [email protected] last edited by
Note that my tests were via groq and the r1 70B distilled llama variant (the 2nd smartest version afaik)
-
[email protected]replied to [email protected] last edited by
It’s because LLMs don’t work with letters. They work with tokens that are converted to vectors.
They literally don’t see the word “strawberry” in order to count the letters.
Splitting the letter probably separates them into individual tokens